This script reproduces the panels of paper’s Supplementary Figures 8 and 9 . Performance of GNN for connectivity matrices with varying sparsity levels. This notebook displays connectivity matrix comparison, \(\phi^*\) plots, \(\psi^*\) plots, and learned embedding for each sparsity level.
Simulation parameters (constant across all experiments):
N_neurons: 1000
N_types: 4 parameterized by \(\tau_i\) ={0.5,1}, \(s_i\) ={1,2} and \(g_i\) =10
N_frames: 100,000
Connectivity weights: random, Cauchy distribution
The simulation follows Equation 2 from the paper:
\[\frac{dx_i}{dt} = -\frac{x_i}{\tau_i} + s_i \cdot \tanh(x_i) + g_i \cdot \sum_j W_{ij} \cdot \tanh(x_j)\]
Variable: Connectivity sparsity
signal_fig_supp_8
5%
signal_fig_supp_8_3
10%
signal_fig_supp_8_2
20%
signal_fig_supp_8_1
50%
signal_fig_2
100%
Configuration
Code
import globprint ()print ("=" * 80 )print ("Supplementary Figure 8: Effect of Connectivity Sparsity" )print ("=" * 80 )# All configs to process (config_name, sparsity) = ['signal_fig_supp_8' , '5%' ),'signal_fig_supp_8_3' , '10%' ),'signal_fig_supp_8_2' , '20%' ),'signal_fig_supp_8_1' , '50%' ),'signal_fig_2' , '100%' ),= []= '' = "./config"
Steps 1-3: Generate, Train, and Plot for all configs
Loop over all sparsity levels: generate data, train GNN, and generate plots. Skips steps if data/models already exist.
Code
for config_file_, sparsity in config_list:print ()print ("=" * 80 )print (f"Processing: { config_file_} ( { sparsity} sparsity)" )print ("=" * 80 )= add_pre_folder(config_file_)# Load config = NeuralGraphConfig.from_yaml(f" { config_root} / { config_file} .yaml" )= config_file= config_fileif device == []:= set_device(config.training.device)= f'./log/ { config_file} ' = f'./graphs_data/ { config_file} ' # STEP 1: GENERATE print ()print ("-" * 80 )print ("STEP 1: GENERATE - Simulating neural activity" )print ("-" * 80 )= f' { graphs_dir} /x_list_0.npy' if os.path.exists(data_file):print (f"data already exists at { graphs_dir} /" )print ("skipping simulation, regenerating figures..." )= device,= False ,= 0 ,= "color" ,= 1 ,= False ,= True ,= 2 ,= True ,else :print (f"simulating { config. simulation. n_neurons} neurons, { config. simulation. n_frames} frames" )print (f"output: { graphs_dir} /" )= device,= False ,= 0 ,= "color" ,= 1 ,= False ,= True ,= 2 ,# STEP 2: TRAIN print ()print ("-" * 80 )print ("STEP 2: TRAIN - Training GNN" )print ("-" * 80 )= glob.glob(f' { log_dir} /models/*.pt' )if model_files:print (f"trained model already exists at { log_dir} /models/" )print ("skipping training (delete models folder to retrain)" )else :print (f"training for { config. training. n_epochs} epochs" )print (f"sparsity: { sparsity} " )= config,= False ,= best_model,= 'color' ,= device# STEP 3: PLOT print ()print ("-" * 80 )print ("STEP 3: PLOT - Generating figures" )print ("-" * 80 )= f' { log_dir} /tmp_results/' = True )= config,= config_file,= ['best' ],= 'color' ,= 'plots' ,= device,= True ,= False # STEP 4: TRAINING PROGRESSION (R² over iterations) print ()print ("-" * 80 )print ("STEP 4: TRAINING PROGRESSION - Computing R² over iterations" )print ("-" * 80 )= f' { log_dir} /results/all/r2_over_iterations.json' if os.path.exists(r2_file):print (f"R² data already exists at { r2_file} " )print ("skipping (delete results/all/ folder to recompute)" )else := config,= config_file,= ['all' ],= 'color' ,= 'plots' ,= device,= True ,= False ,
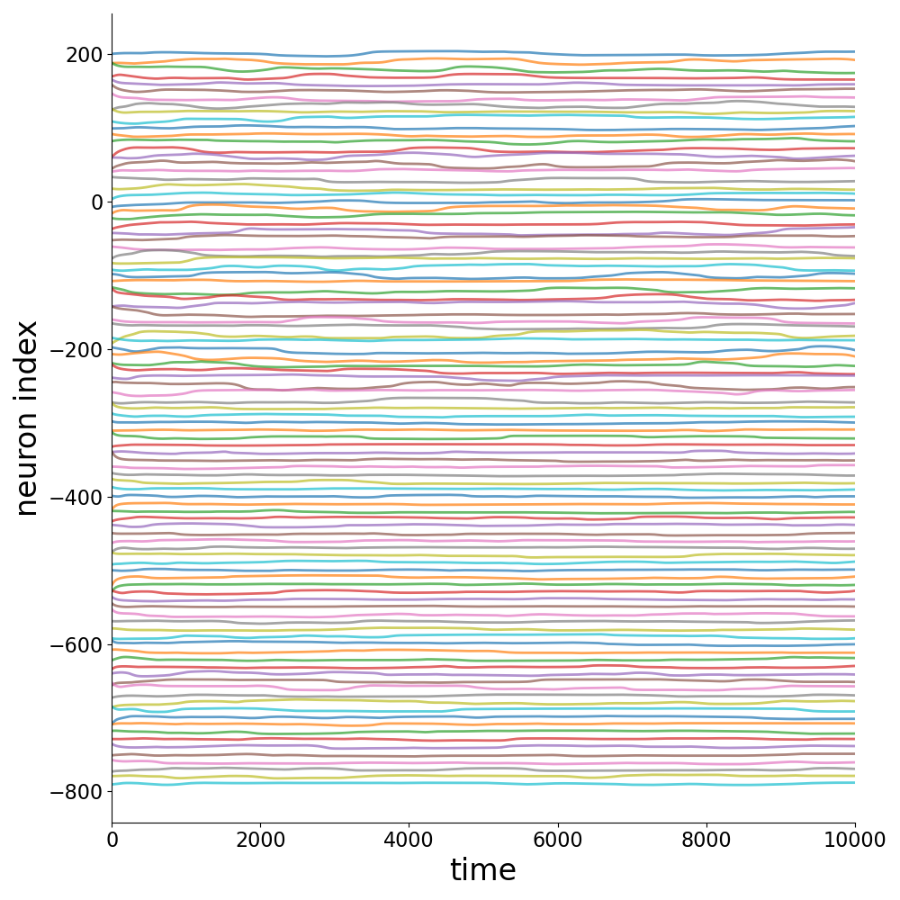
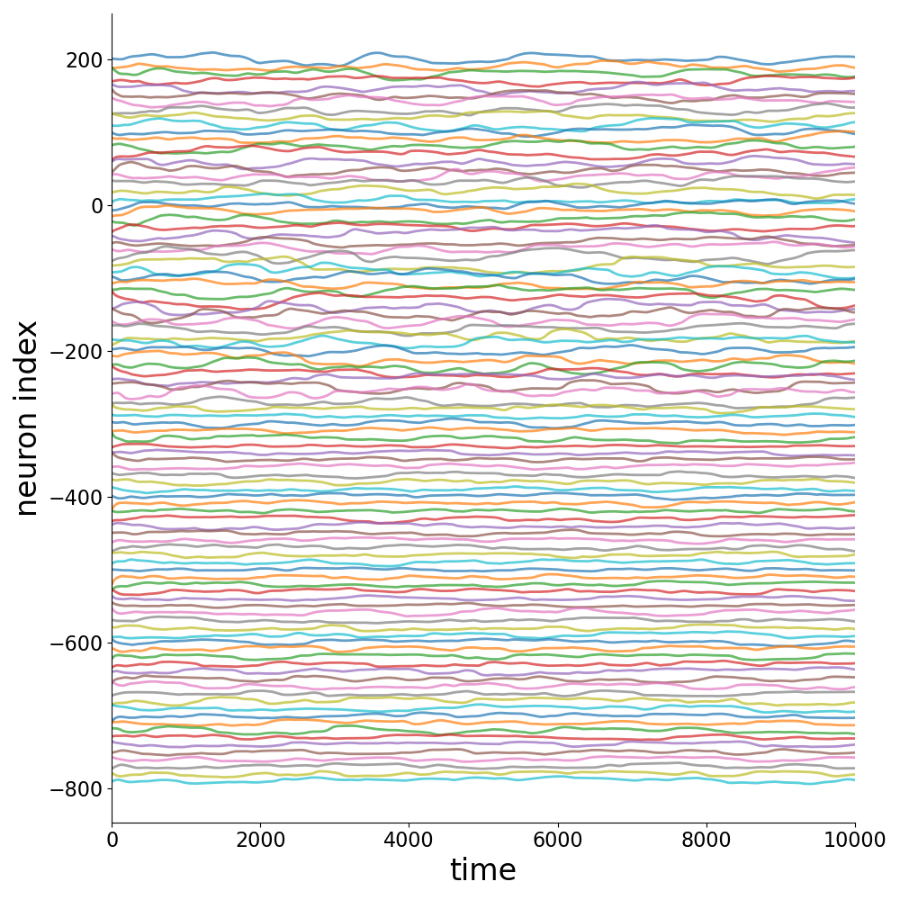
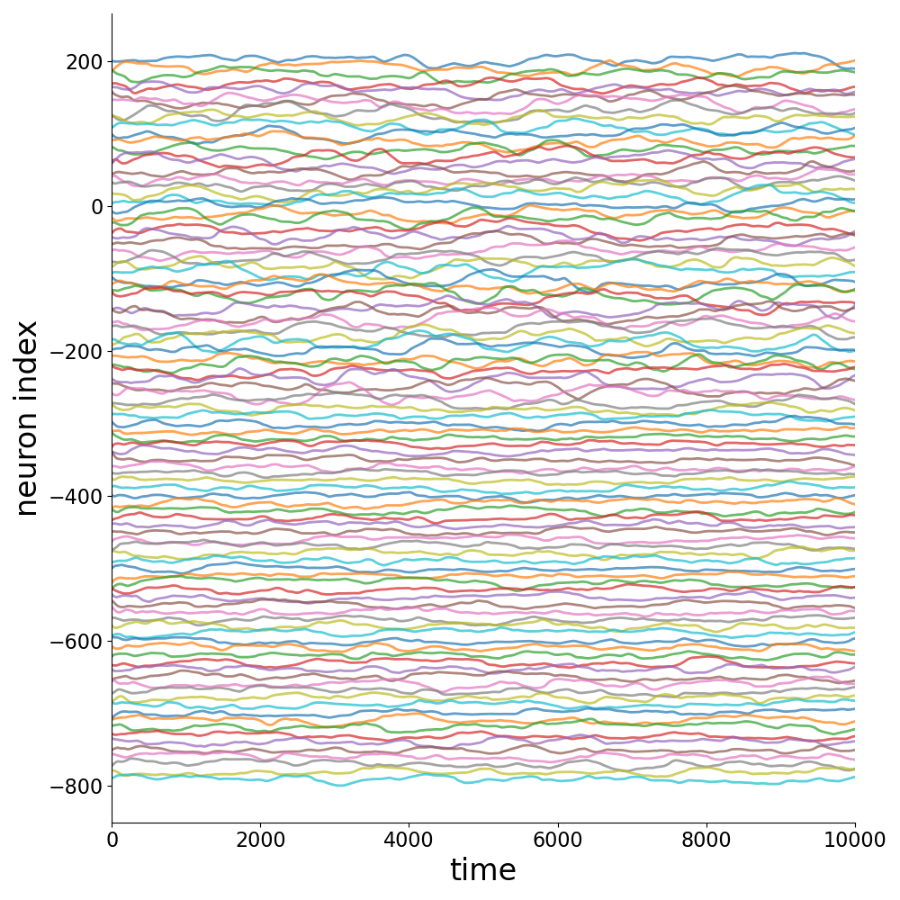
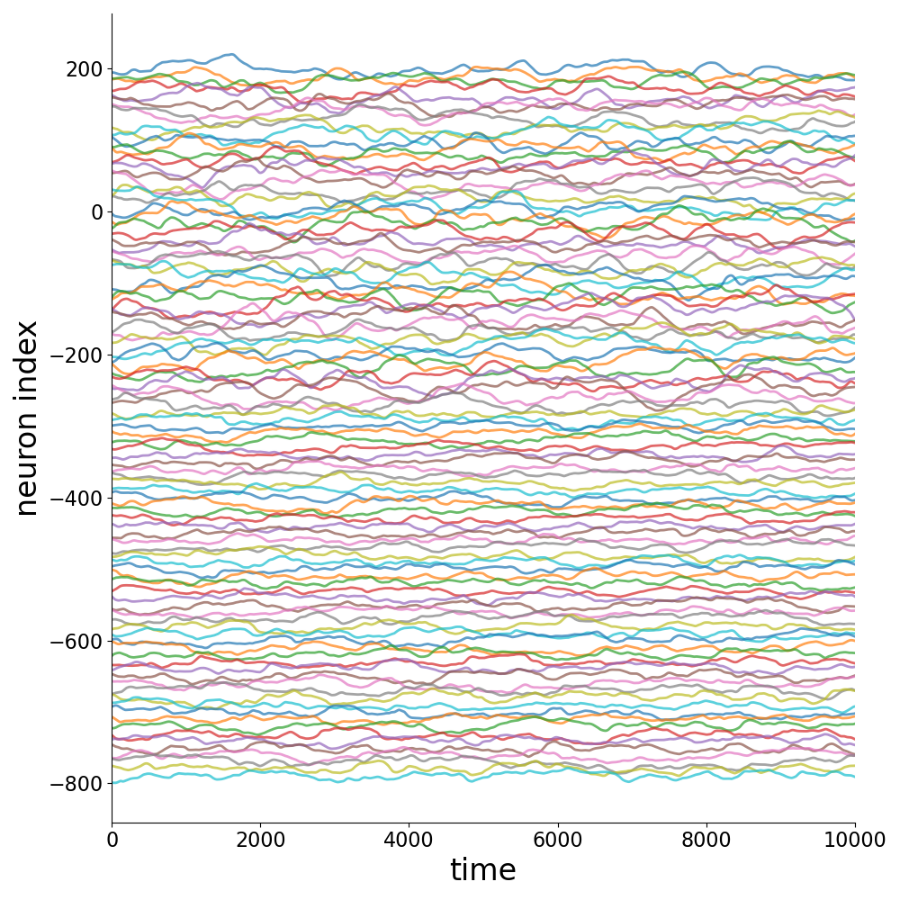
Activity Time Series
Sample of 100 time series for each sparsity level.
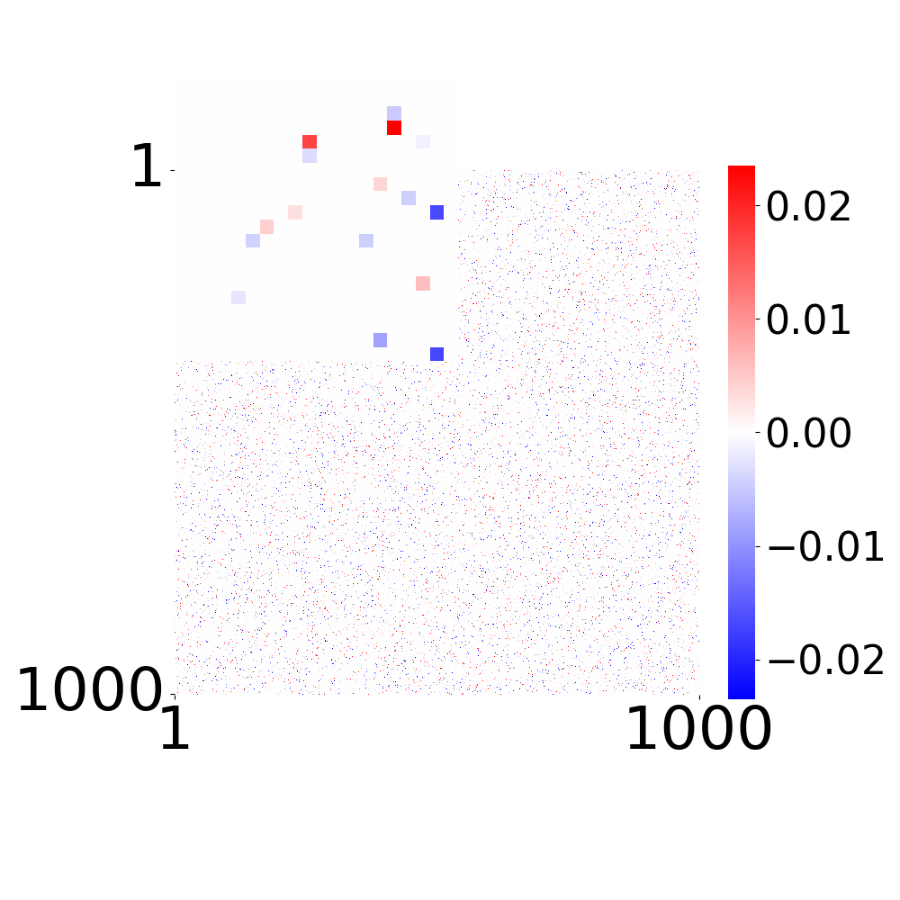
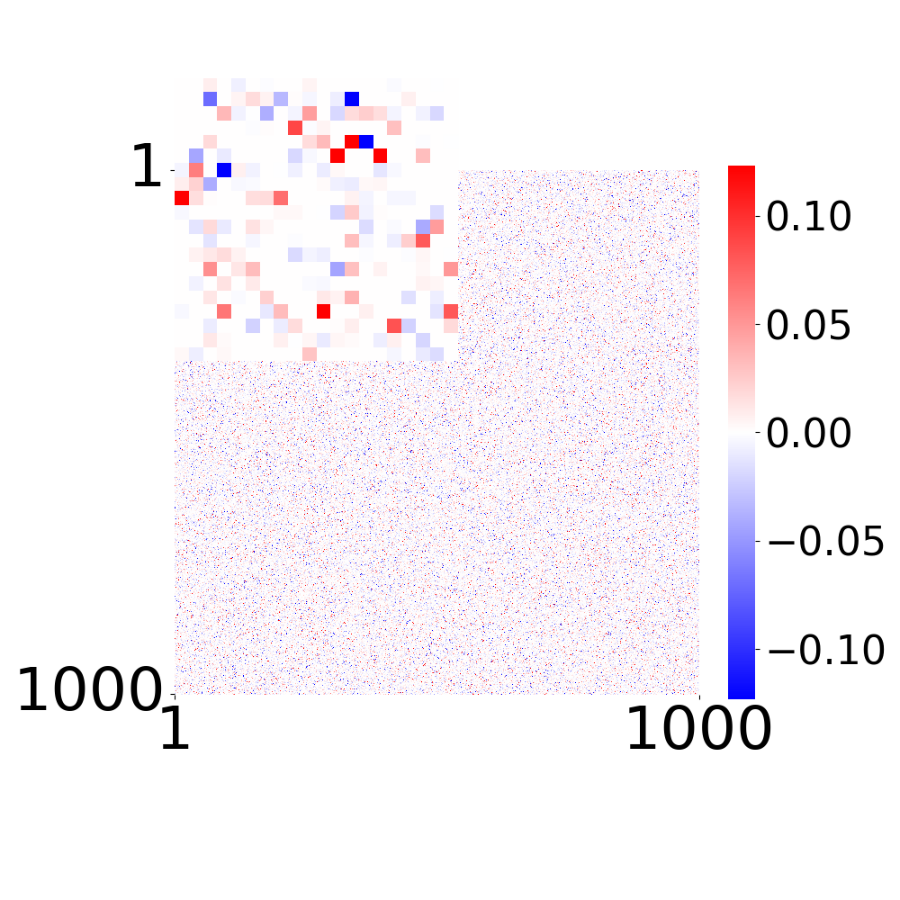
True Connectivity Matrix \(W_{ij}\)
True connectivity matrix for each sparsity level.
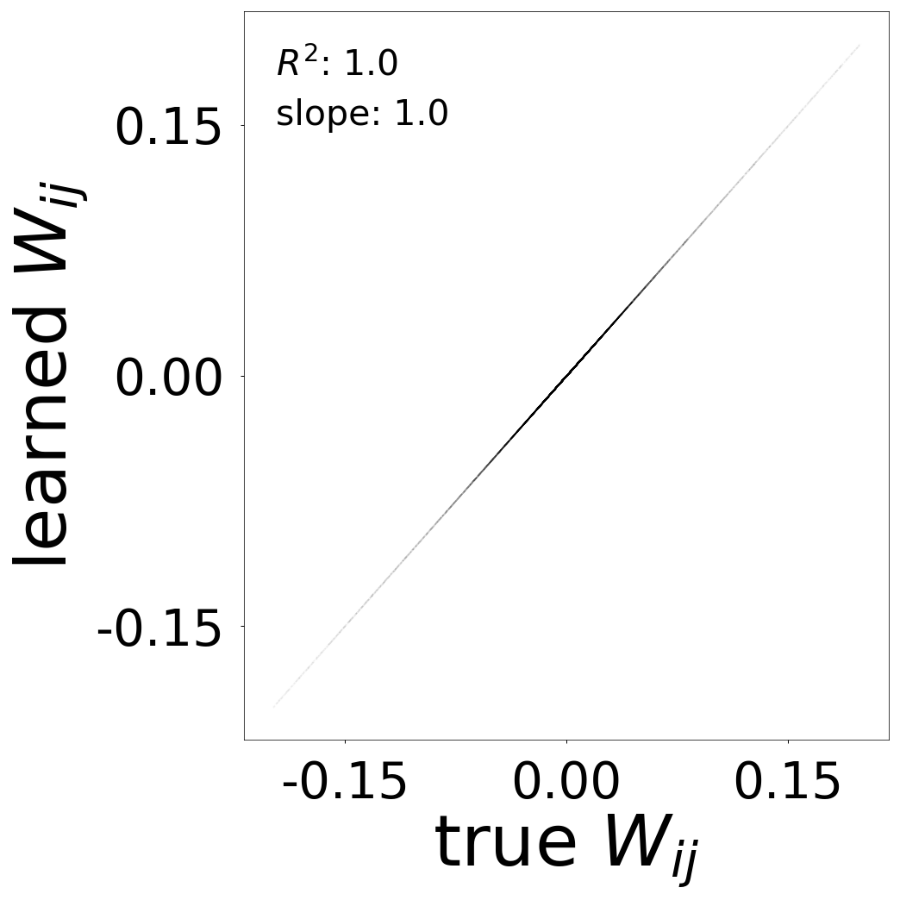
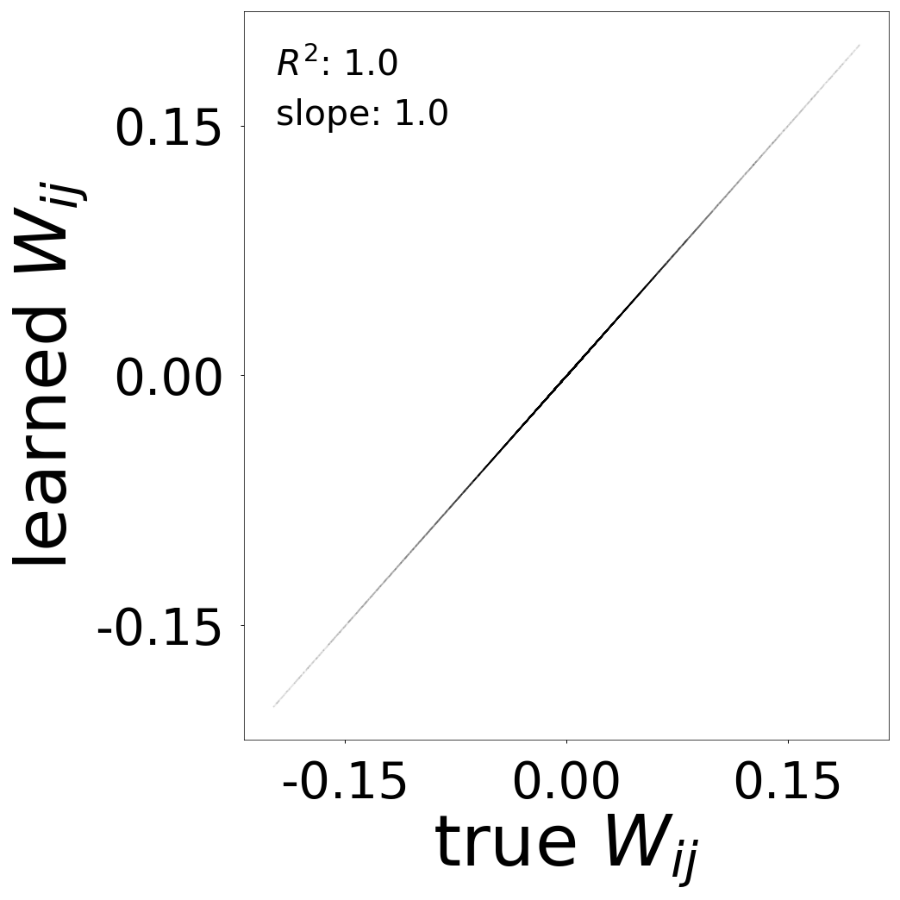
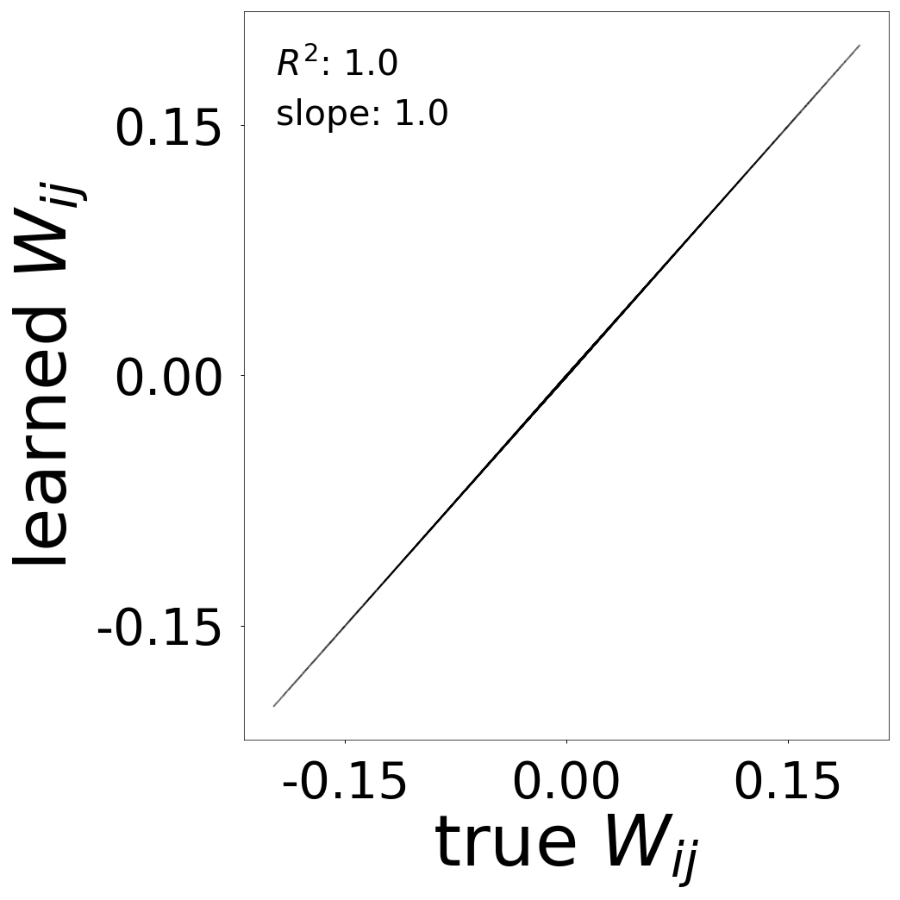
Connectivity Matrix Comparison
Learned vs true connectivity matrix \(W_{ij}\) after training. The scatter plot shows \(R^2\) and slope metrics.
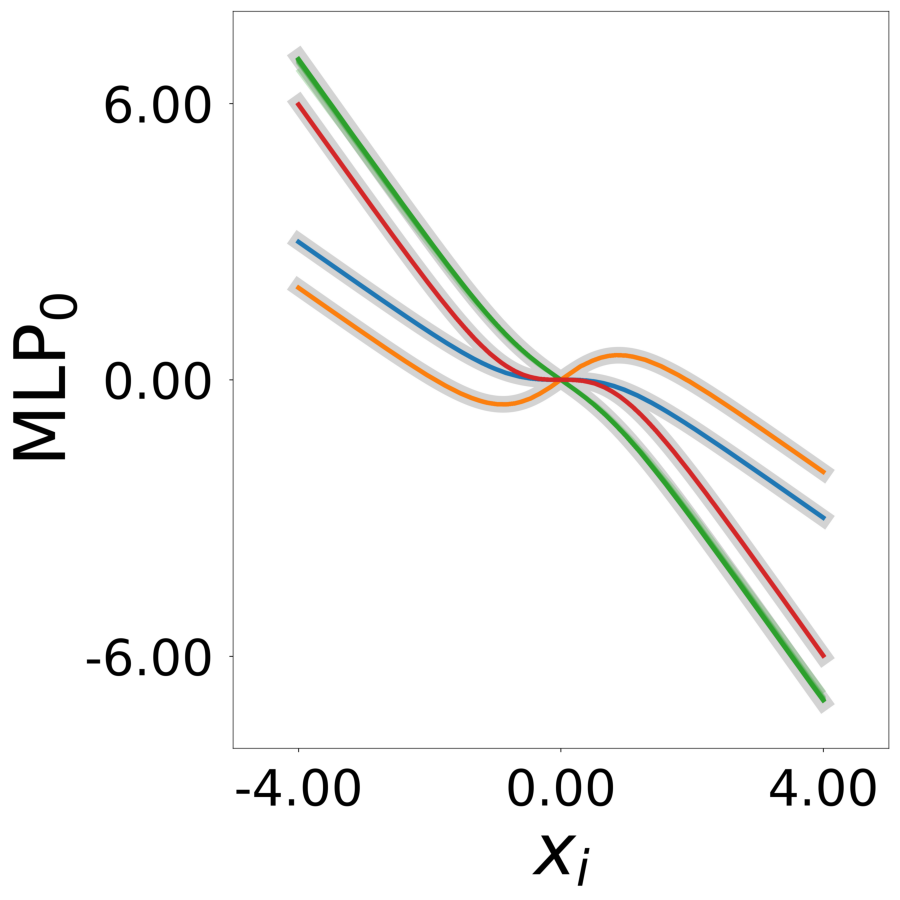
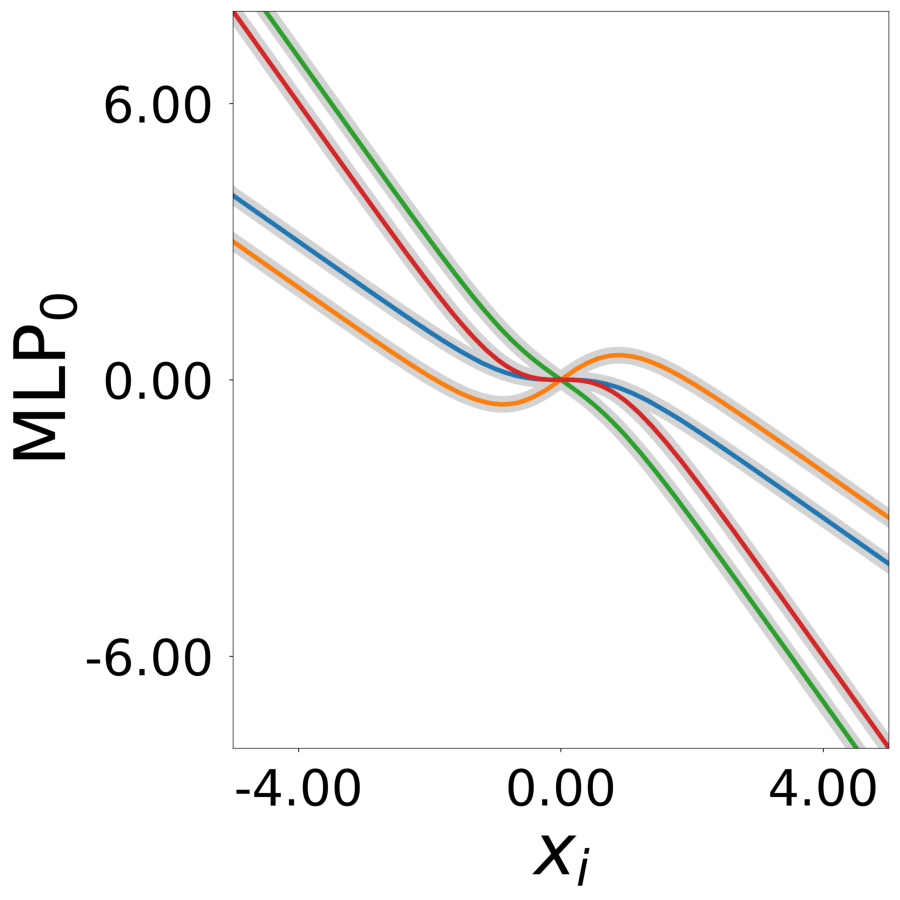
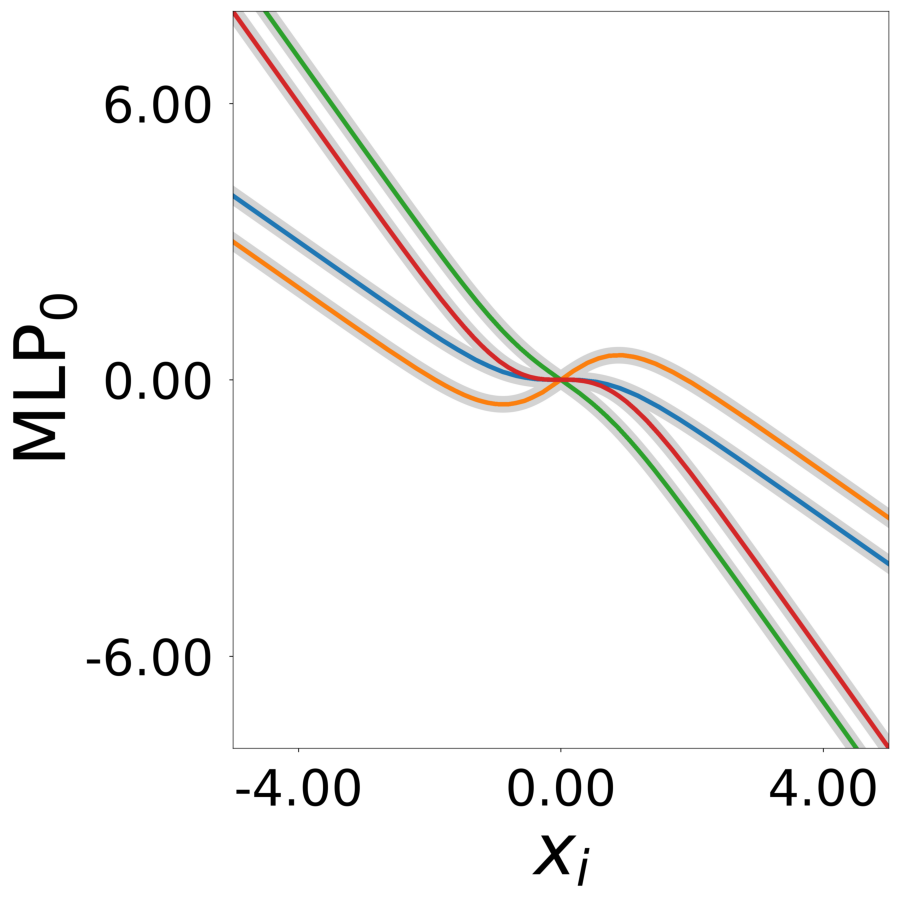
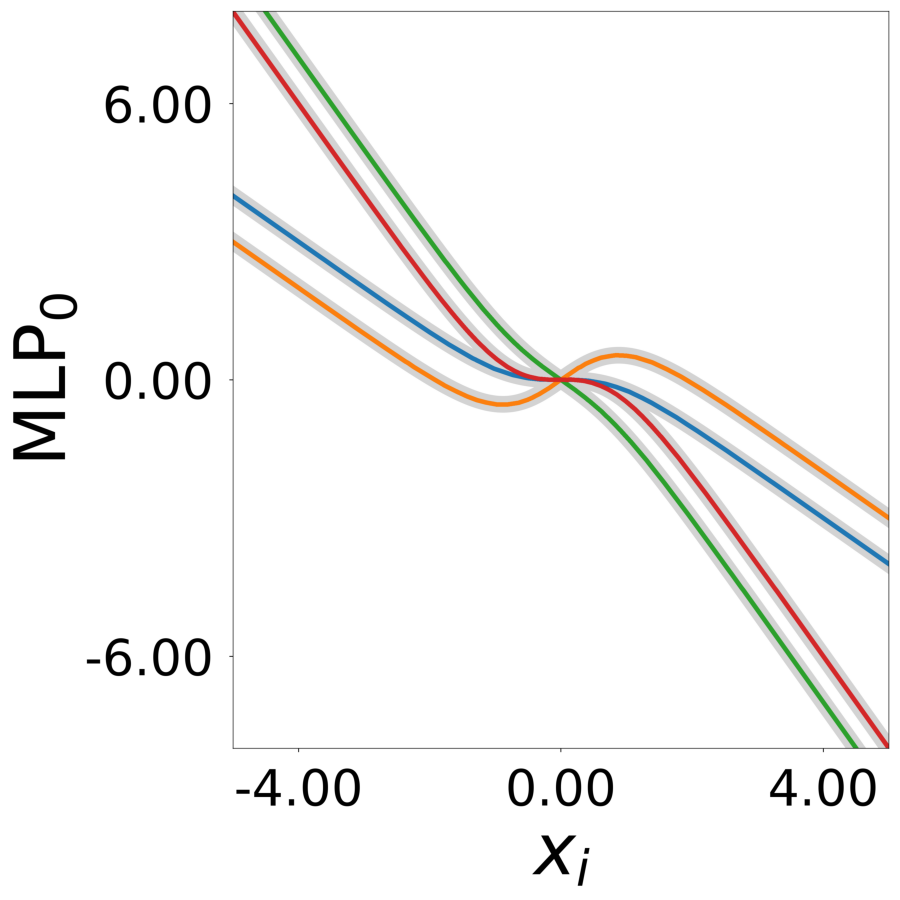
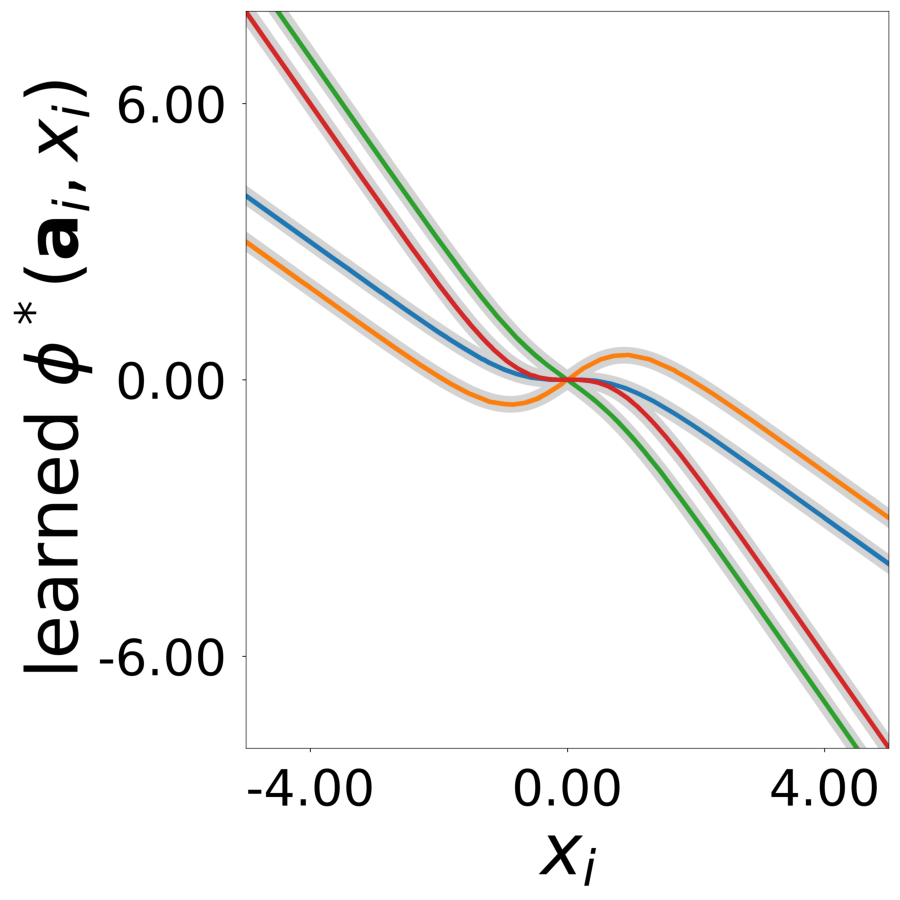
Update Function \(\phi^*(\mathbf{a}_i, x)\) (MLP0)
Learned update functions after training. Each curve represents one neuron. Colors indicate true neuron types. True functions overlaid in gray.
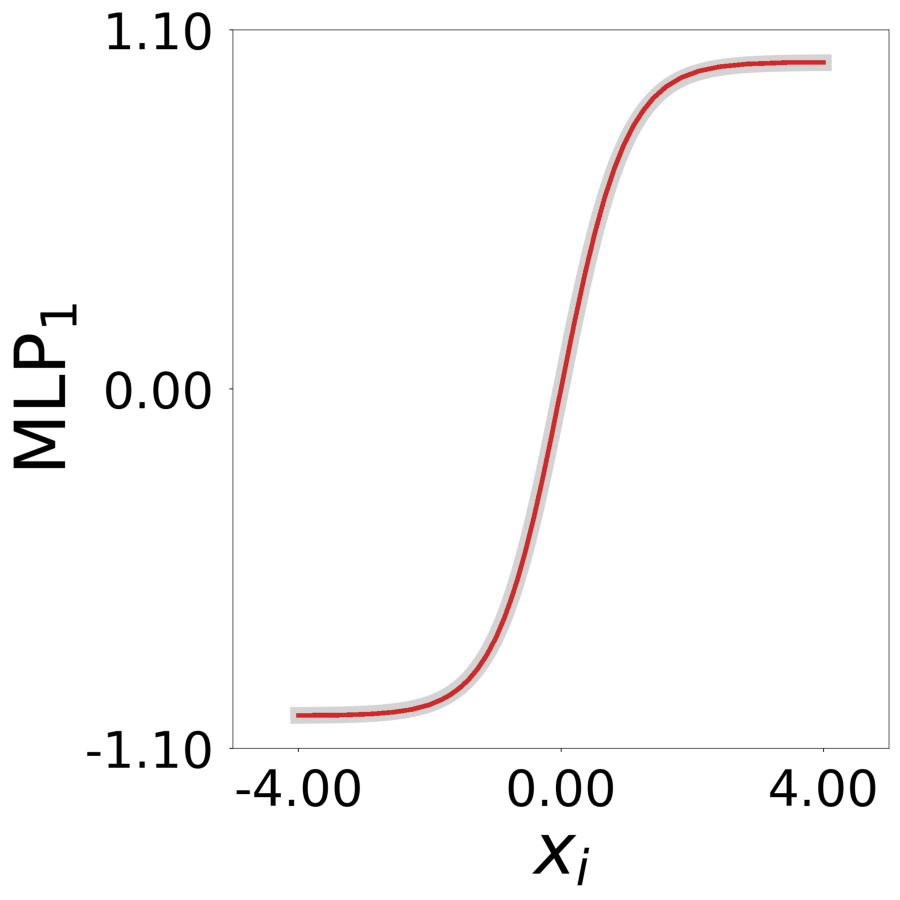
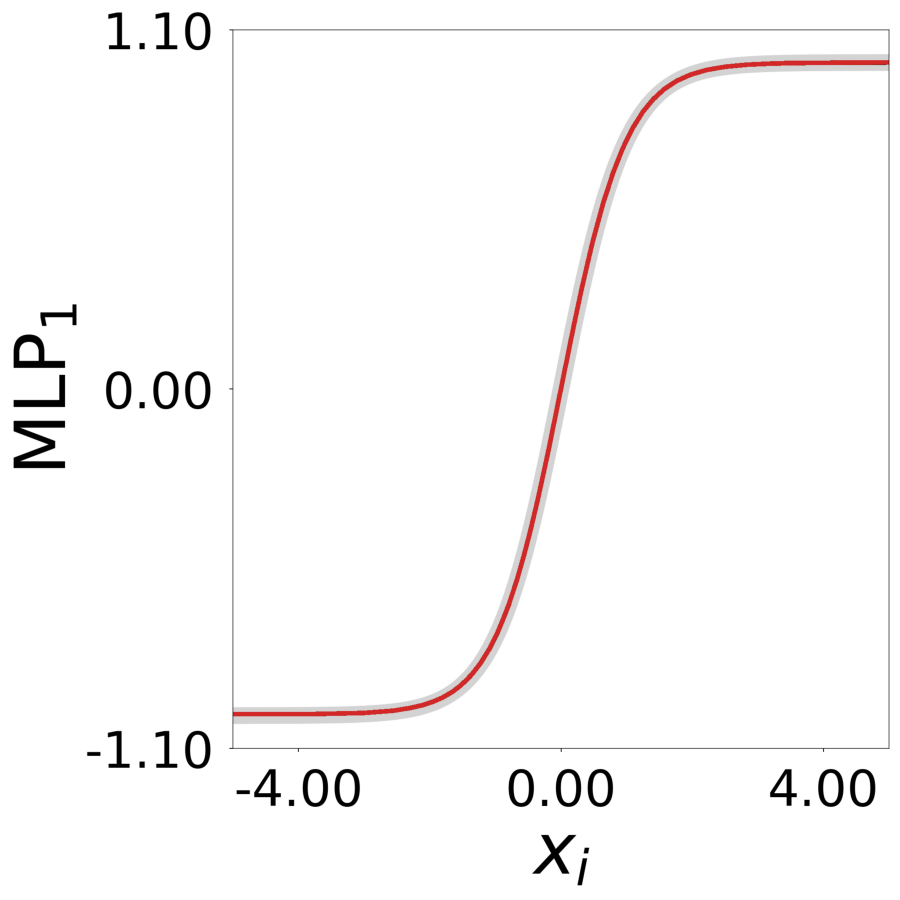
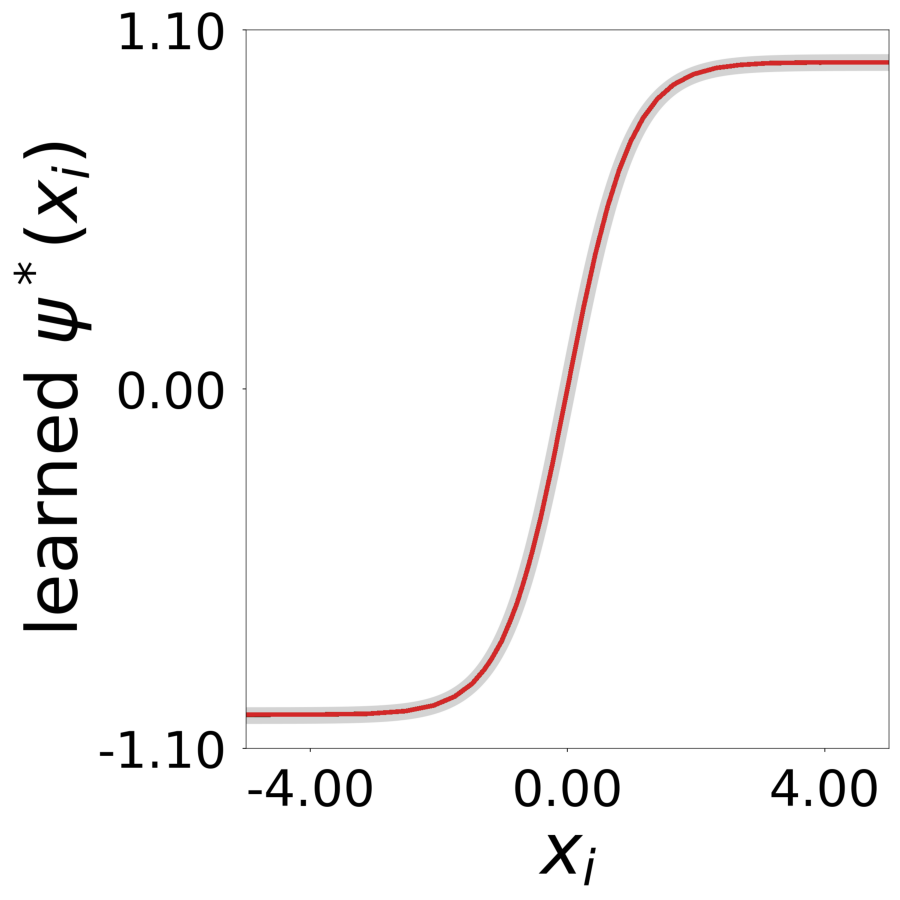
Transfer Function \(\psi^*(x)\) (MLP1)
Learned transfer function after training, normalized to max=1. True function overlaid in gray.
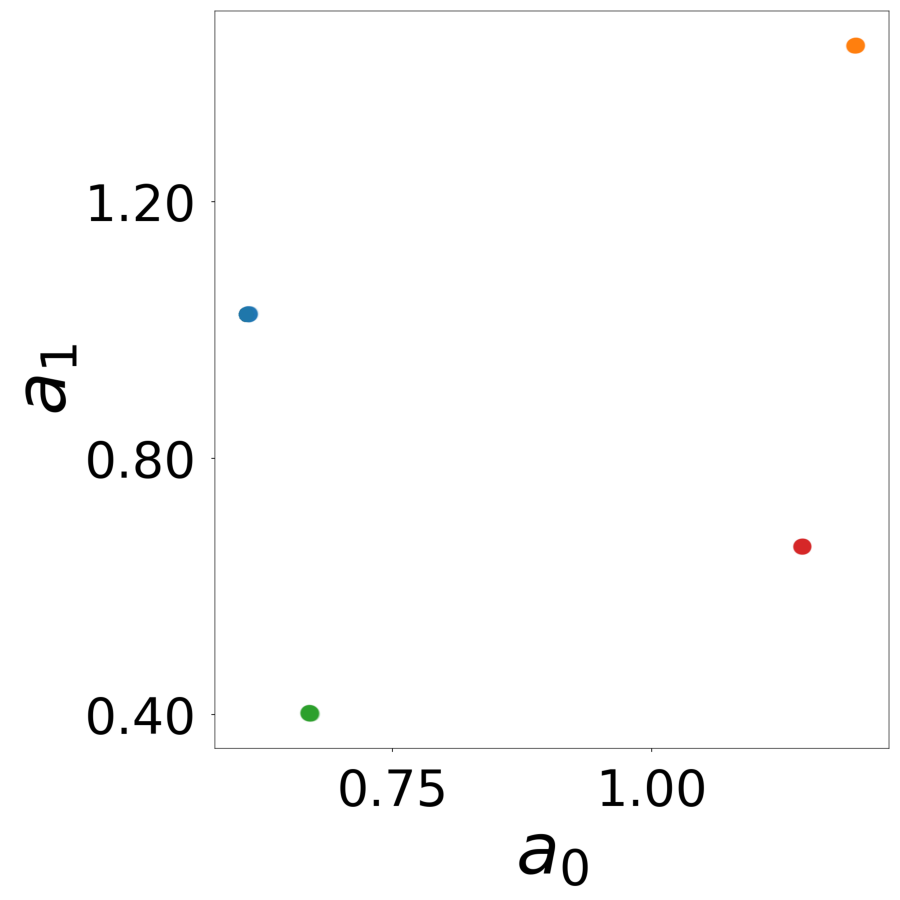
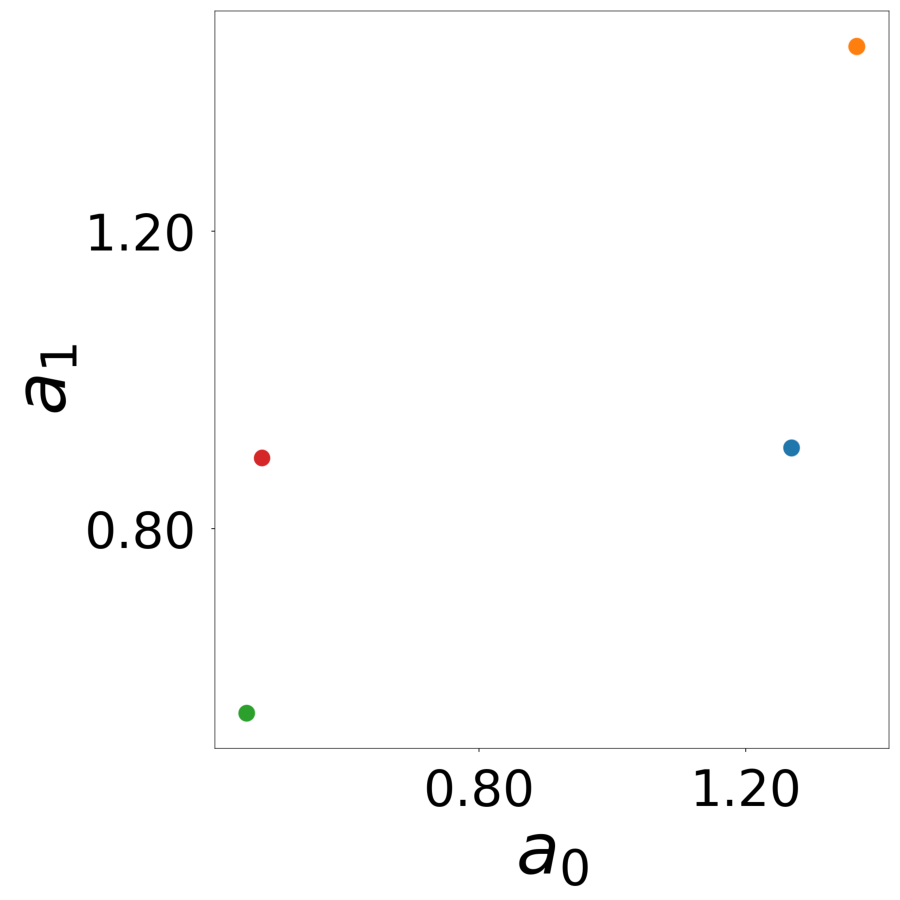
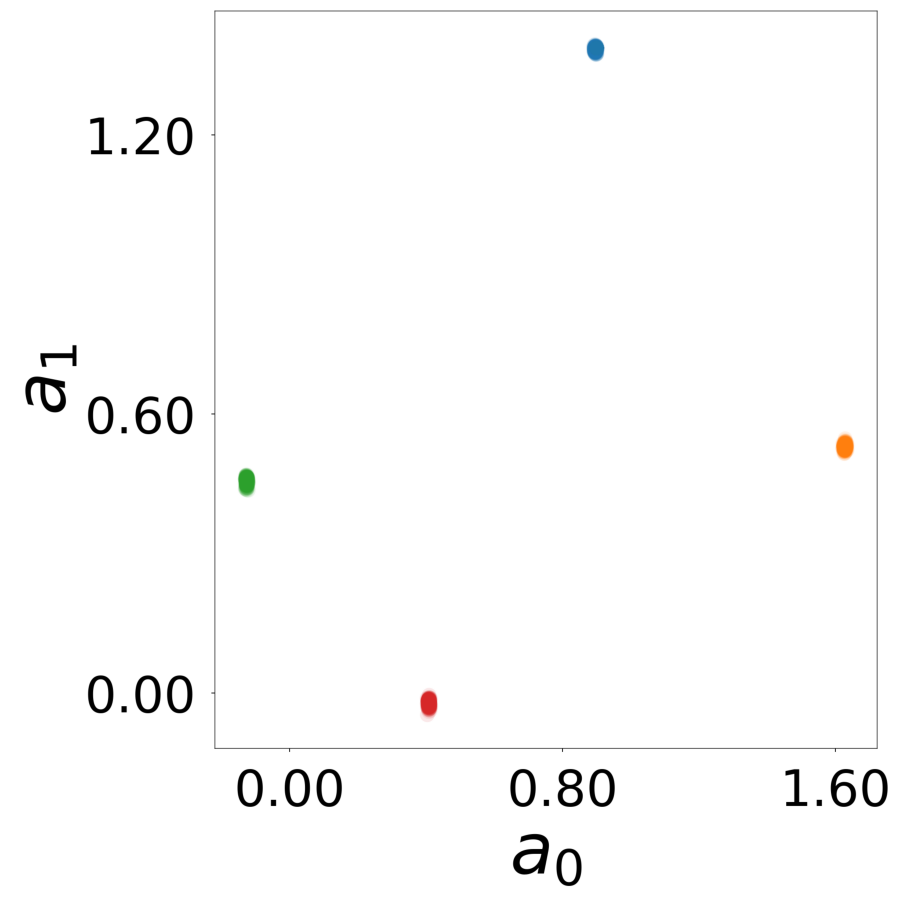
Latent Embeddings \(\mathbf{a}_i\)
Learned latent vectors for all neurons. Colors indicate true neuron types.
R² Connectivity Over Training Iterations
1000 densely connected neurons with 4 neuron-dependent update functions. The plot displays \(R^2\) for the comparison between true and learned connectivity matrices \(W_{ij}\) as a function of training iterations for different connectivity filling factors (colors). All comparisons are made at equal numbers of gradient descent iterations.
Code
print ()print ("-" * 80 )print ("Generating R² over iterations comparison plot" )print ("-" * 80 )= plot_r2_over_iterations(= config_list,= './log/signal/tmp_results/r2_over_iterations_sparsity.png' ,= device,